TLE-Lite、TLE-Struct 和 TLE-Raw#
本节介绍 TLE-Lite、TLE-Struct 和 TLE-Raw 以及它们在编译过程中的处理方式。
TLE-Lite、TLE-Struct 和 TLE-Raw 简介#
TLE-Lite、TLE-Struct 和 TLE-Raw 是编译器语言,位于 AI 生态系统的中间层。上层通过图编译器和算子库连接 AI 框架,下层连接各种硬件运行时。
下图展示了 TLE-Lite、TLE-Struct 和 TLE-Raw 在 AI 生态系统中的位置。
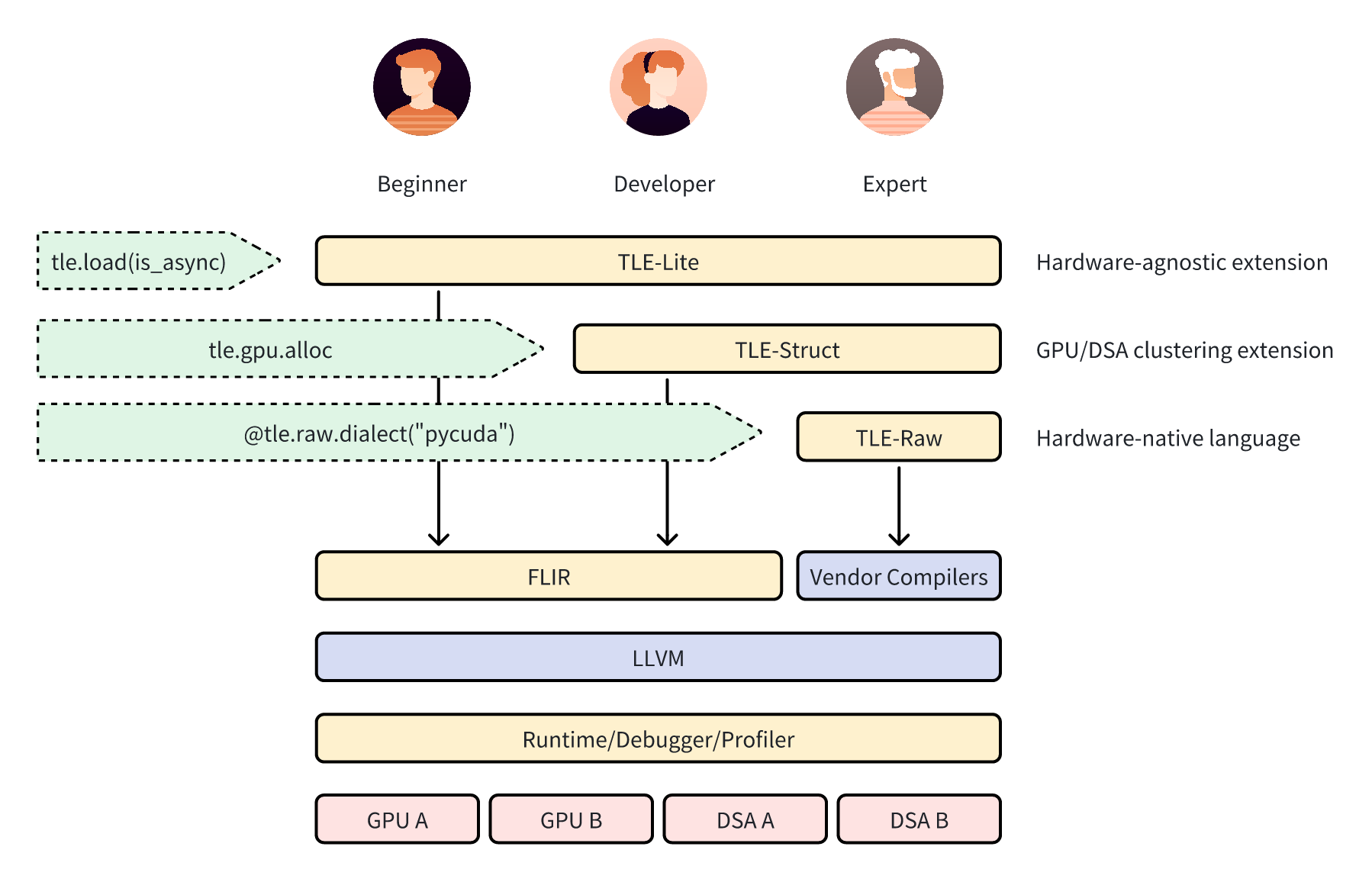
这三种编译器语言为不同用户提供了不同级别的性能优化:
TLE-Lite 允许用户以最小的改动修改现有的 Triton 内核,同时兼容各种硬件后端。可供算法工程师在快速优化场景中使用。
TLE-Struct 允许用户为不同硬件架构(如 GPGPU 和 DSA)的不同集群显式定义计算与数据之间的结构化映射。可供对目标硬件特性和优化有一定了解的开发者使用。
TLE-Raw 允许用户直接修改厂商的原生编程语言。可供对目标硬件有深入了解的开发者使用,这些开发者主要是性能优化专家。
Hints、TLE-Lite 和 TLE-Struct 最终将通过 FLIR(即 FlagTree IR)lowering 到 LLVM(低级虚拟机)IR(中间表示),而 TLE-Raw 将通过相应语言的编译管线(如厂商的私有编译器)lowering 到 LLVM IR。最终,它们将被链接在一起,共同生成一个完整的内核,供运行时加载和执行。
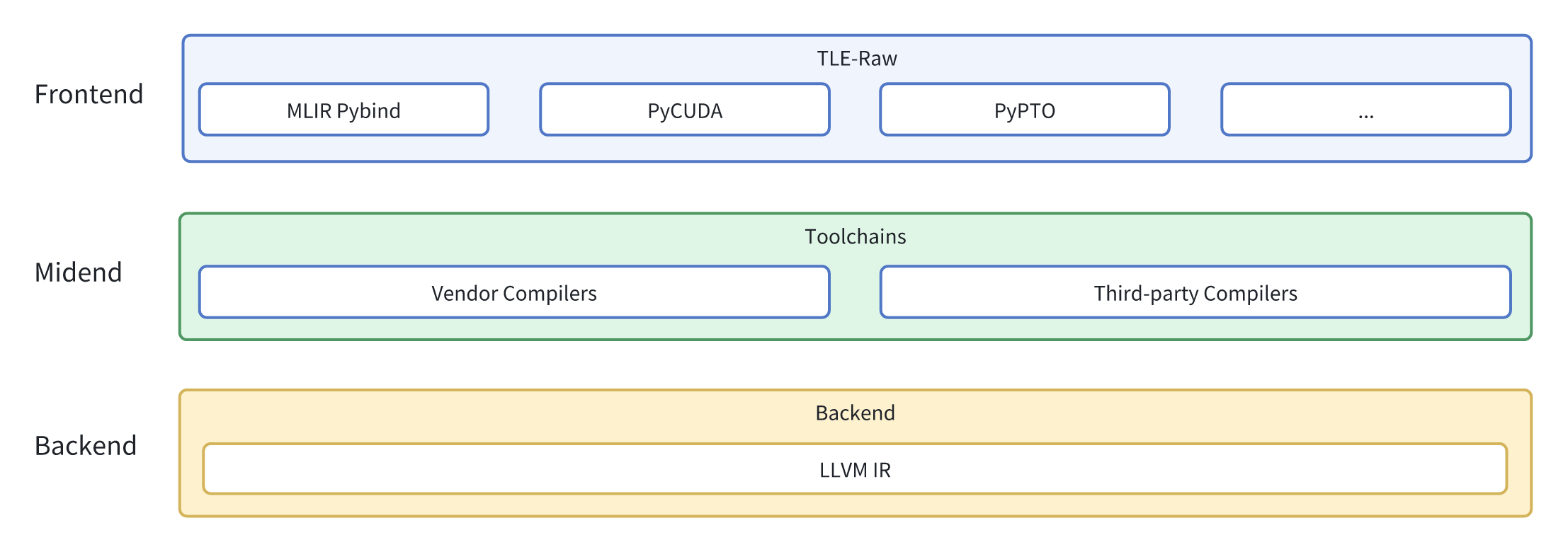
下图展示了 TLE-Raw 与现有 DSL(TileLang 和 cuTile)以及必要的库和工具(PyCUDA 和 MLIR Pybind)的兼容性,以及其在 AI 生态系统中的位置。
有关如何使用 TLE,请参见使用 TLE-Lite、使用 TLE-Struct 和使用 TLE-Raw。
TLE 在编译过程中的处理#
目的和范围
扩展 Triton,提供显式的共享内存和张量内存管理、通过张量内存加速器(TMA)进行异步数据移动,以及针对 NVIDIA Hopper 级 GPU 优化的流水线控制(目前)。
前端 API 位于
tle下,lowering 到自定义 MLIR 方言,并由tle下的 Pass 处理。
前端 DSL 层(Python)
tle.language.core重写了关键的tl内置函数,以附加额外的属性(例如"tt.load.async"),并返回表示共享或张量内存分配的buffered_tensor句柄(core.py)。例如,关键的tl内置函数包括load、alloc、copy、local_load、local_store和循环辅助函数。GPU 特定的辅助函数在 GPU 中定义布局(
swizzled_shared_layout、nv_mma_shared_layout等)、作用域(smem、tmem)以及buffered_tensor语义。这些语义包装了 IR memdesc 类型,同时保持 Triton 风格的类型检查。用户在
@triton.jit内核中导入这些符号(例如tle.alloc、tle.copy、tle.pipeline),以分配 SMEM 瓦片、启动异步拷贝或编排分阶段循环。
语义验证
semantic.py中的TLESemantic与 Triton 的语义层并行运行。它在 lowering 之前验证形状、数据类型和拷贝兼容性,提供早期错误消息并适配 constexpr 输入。语义辅助函数调用自定义 builder 钩子(通过 C++ 桥接暴露),以生成
LocalAllocOp、TMACopyOp等,确保 Python API 与 TTIR 构造一一映射。
TLE-Raw 和 EDSL 层
TLE-Raw(raw)暴露了一个轻量级的基于 MLIR 的 EDSL(嵌入式领域特定语言),用于直接编写方言特定的内建函数。像
@dialect(name="mlir")这样的装饰器通过EdslMLIRJITFunction从 Python AST 构建 LLVM IR,使后端开发者能够在高层 Triton 语法之外原型化内核或辅助操作。TLE-Raw 运行时(
call()辅助函数)物化tle::DSLRegionOp节点,其主体随后由 Pass 内联。
C++ 桥接和方言
triton_tle.cc在 Triton 的TritonOpBuilder上注册了额外的 builder 方法(创建编码属性、memdesc 类型、TMACopy 操作、DSL 区域),并通过pybind11将新的 Pass 和原始 IR 辅助函数连接到 Python。MLIR 方言位于 dialect 目录中,包含 IR 定义以及 Analysis、Conversion 和 Transforms 基础设施,与上游 Triton 的惯例保持一致。
Pass 和 Lowering 管线
Pass 注册在
Passes.td中定义,并作为 Python API 暴露,包括add_early_assign_memory_space、add_lower_async_load、add_lower_tma_copy、add_tle_convert_arg_to_memdesc、add_tle_dsl_region_inline。关键转换:
Early Assign Memory Space 将标记为
tt.memory_space="shared_memory"的张量重写为显式的本地分配和存储序列,并移除该属性,为后续 Pass 暴露具体的 SMEM 操作(TleEarlyAssignMemorySpace.cpp)。Lower Async Load 查找标记为
"tt.load.async"(由tle.load设置)的加载操作,并将其转换为 Hopper 风格的异步拷贝加提交或等待链,为LocalLoadOps提供数据。它还会去重冗余分配(TleLowerAsyncLoad.cpp)。Lower TMA Copy 将高层
TMACopyOp(由tle.copy使用张量描述符生成)lowering 为 NVIDIA TMA 内建函数,处理 GM→SMEM 和 SMEM→GM 两个方向,并进行屏障管理(TleLowerTmaCopy.cpp)。Convert Arg To MemDesc 通过插入临时的本地分配和加载序列,在 DSL 区域内物化兼容 memdesc 的操作数和结果。这使得通用的 Triton Pass 能够对这些操作数和结果进行推理(
ConvertArgToMemDesc.cpp)。DSL Region Inline 将
tle::DSLRegionOp主体拼接到周围的 CFG(控制流图)块中,在 TLE-Raw 内核被 lowering 后,将 yield 替换为分支(DSLRegionInline.cpp)。
后端分发
后端特定逻辑目前针对 NVIDIA(参见
nvidia以及在 Pass 内部使用triton::nvidia_gpu内建函数)。其他硬件后端可以通过复用 TLE-Raw DSL 和 Pass 钩子,并在third_party/<backend>/backend/compiler.py下实现自己的 lowering Pass 和编码来添加。此扩展机制与 HINTS 的分发方式类似。从
triton_tle.cc导出的 Pass 包装器允许每个后端在组装其管线时仅选择其支持的 Pass。例如,NVIDIA 启用 TMA lowering,而其他后端可能在内存空间标记后停止。
测试和示例
tle下的集成测试涵盖流水线循环、GEMM 和 TMA 拷贝的端到端内核。这些测试确保 Python API、语义检查和 Pass 之间的一致性。开发者在修改 Python DSL 或 MLIR Pass 后,可以运行
python/test/tle/run_tests.py来快速捕获回归问题。
扩展 TLE
新的 API 应遵循既定的模式:添加带有语义验证的 Python 表面操作 → 暴露必要的 builder 钩子 → 创建和扩展方言操作 → 添加 lowering Pass 并为后端注册。
将布局和作用域抽象集中在
types.py中,以便在不触及用户代码的情况下切换未来的硬件(例如张量内存),并在Passes.td中记录任何新的 Pass。