功能特性#
SGLang 的推理引擎依赖 NVIDIA 专用组件:flashinfer 用于注意力计算,sgl_kernel 用于融合 CUDA 内核,NCCL 用于分布式通信。在其他硬件(华为昇腾、寒武纪 MLU、Iluvatar 等)上运行原本需要对源码进行侵入式修改。
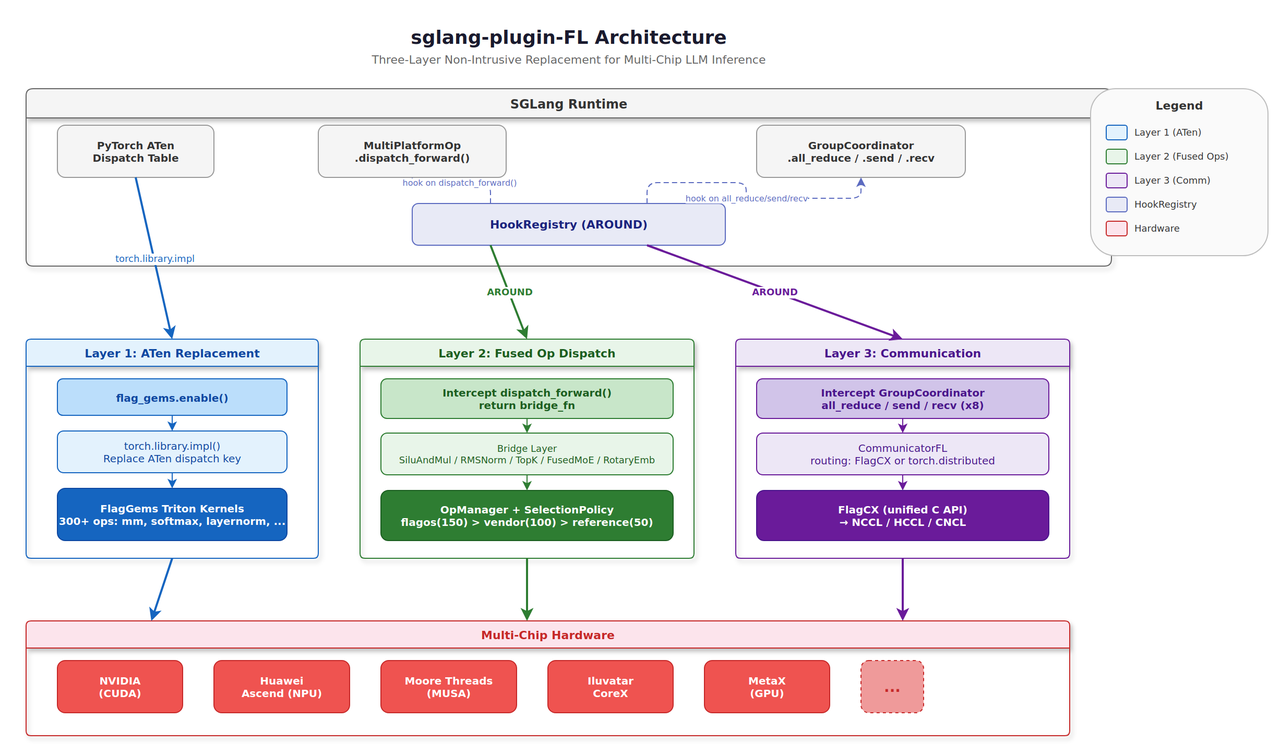
本插件通过三个层次的替换提供了非侵入式的适配层:
第一层 — ATen 算子#
通过 PyTorch 的调度机制,用 FlagGems Triton 内核替换 PyTorch 的低级算子(matmul、softmax、embedding 等)。当调用 flag_gems.enable() 时,PyTorch 调度表会为 ATen 算子注册 Triton 内核,无需修改代码即可提供硬件加速实现。
第二层 — SGLang 融合内核#
通过 HookRegistry AROUND 钩子拦截 SGLang 的自定义融合算子(SiluAndMul、RMSNorm、RotaryEmbedding),经过标准化调度系统(与 vllm-plugin-FL 对齐)路由,选择最佳可用后端:
FlagGems — 基于 Triton 的实现(默认,最高优先级)
Vendor — 芯片原生实现(例如 CUDA sgl_kernel、昇腾 CANN)
Reference — 纯 PyTorch 回退实现
第三层 — 分布式通信#
用 CommunicatorFL(基于 FlagCX 或 torch.distributed)替换基于 NCCL 的集合通信,支持任意硬件上的多卡推理。支持 all_reduce、all_gather、reduce_scatter、send 和 recv 操作。
芯片厂商只需实现一个后端类 + register_ops.py。调度系统的自动发现机制会处理其余部分。同一厂商实现可同时用于 sglang-plugin-FL 和 vllm-plugin-FL。