用户指南#
环境配置#
参见 快速开始 页面中的环境配置部分。
安装与编译#
参见 快速开始 了解 FlagCX 编译和安装。
API 参考#
设备句柄管理#
FlagCX 引入了设备句柄 API,将设备/CCL 适配器生命周期与通信器管理分离。之前的 flagcxHandlerGroup 方式现已弃用。
新 API(推荐)#
// 初始化设备句柄 — 加载设备/CCL 适配器插件
flagcxResult_t flagcxDeviceHandleInit(flagcxDeviceHandle_t *devHandle);
// 释放设备句柄 — 终结设备/CCL 适配器插件
flagcxResult_t flagcxDeviceHandleFree(flagcxDeviceHandle_t devHandle);
使用模式:
flagcxDeviceHandle_t devHandle;
flagcxDeviceHandleInit(&devHandle);
// ... 使用设备操作(setDevice、getDeviceCount 等)...
flagcxCommInitRank(&comm, nranks, uniqueId, rank);
// ... 通信操作 ...
flagcxCommDestroy(comm);
flagcxDeviceHandleFree(devHandle);
弃用的 API#
以下 API 已弃用,将在未来版本中移除:
// 已弃用 - 改用 flagcxDeviceHandleInit/Free
struct flagcxHandlerGroup {
flagcxUniqueId_t uniqueId;
flagcxComm_t comm;
flagcxDeviceHandle_t devHandle;
};
flagcxResult_t flagcxHandleInit(flagcxHandlerGroup_t *handler);
flagcxResult_t flagcxHandleFree(flagcxHandlerGroup_t handler);
变更的 API#
// 参数现在按值传递,而非指针
// 旧:flagcxGetUniqueId(flagcxUniqueId_t *uniqueId);
// 新:
flagcxResult_t flagcxGetUniqueId(flagcxUniqueId_t uniqueId);
注意:调用者必须提供指向 flagcxUniqueId 结构体的有效指针。
移除的 API#
以下 API 已从公共接口中移除:
flagcxCommFifoBuffer()— 不再属于公共 API
使用 FlagCX 进行同构测试#
通信 API 测试#
构建与安装
参见 快速开始 中的通信 API 测试构建与安装部分。
通信 API 测试
mpirun --allow-run-as-root -np 2 ./test_allreduce -b 128K -e 4G -f 2 -p 1
说明
test_allreduce是基于 MPI 和 FlagCX 构建的 AllReduce 操作性能基准测试。 每个 MPI 进程绑定到单个 GPU。 程序运行预热迭代,然后在用户定义的消息大小范围(最小、最大和步长)内进行计时测量。对于每个消息大小,基准测试报告:
平均延迟
估计带宽
用于正确性验证的缓冲区片段
例如,在 2 个 GPU 上使用 2 个 MPI 进程运行
test_allreduce,从 128 KiB 开始,每步将消息大小翻倍(128 KiB、256 KiB、512 KiB、1 MiB …)直到 4 GiB。 对于每个大小,基准测试记录带宽、延迟和正确性结果。正确的性能测试输出
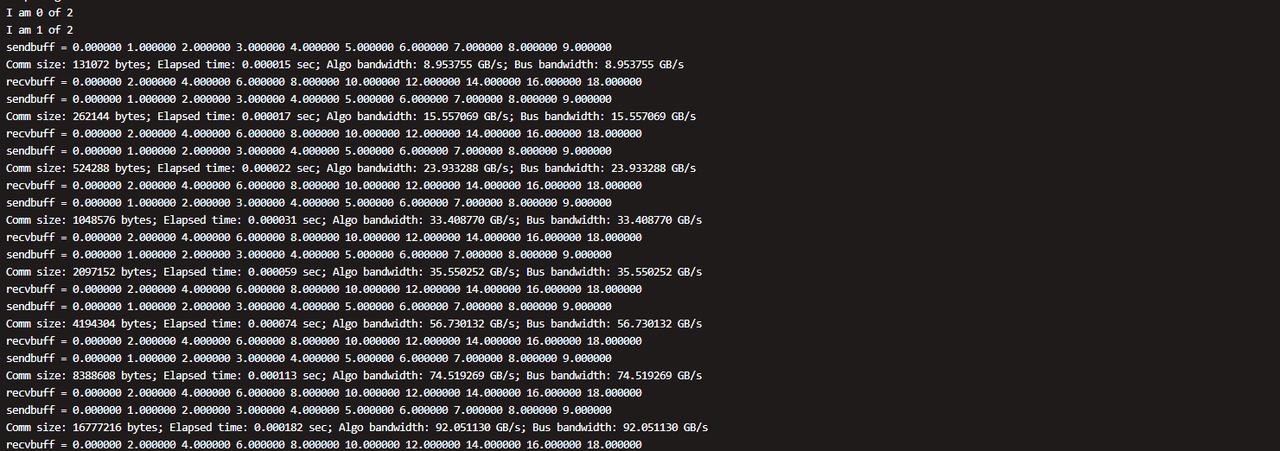
执行过程中遇到的问题
执行过程中,当 OpenMPI 尝试通过 InfiniBand(openib BTL)建立连接但找不到可用的 CPC(连接协议)时,可能会看到断言警告。 在这种情况下,IB 端口会自动禁用。此警告不影响性能测试结果。

解决方案
要抑制此警告,请在
mpirun命令中添加以下选项以禁用openib并回退到 TCP。--mca btl ^openib
MPI 错误警告
如果在执行过程中遇到 MPI 错误,有两种可能的解决方案:
检查本地 MPI 安装
验证本地 MPI 安装路径并设置适当的环境变量。
安装 MPI
如果未安装 MPI 或本地安装不合适,下载并安装 MPI。
按照以下说明操作:
wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.6.tar.gz tar -zxf openmpi-4.1.6.tar.gz cd openmpi-4.1.6 ##配置并构建 ./configure --prefix=/usr/local/mpi make -j$(nproc) sudo make install
Torch API 测试#
构建与安装
参见 快速开始 了解 Torch API 测试的构建与安装说明。
Torch API 测试执行
测试用例位于构建/安装目录中。
cd ./example/example.py
测试脚本
run.sh根据当前平台设置环境变量和设备 ID。 您可能需要修改这些变量以匹配您的硬件设置。#!/bin/bash # 检查是否设置了调试标志 if [ "$1" == "debug" ]; then export FLAGCX_DEBUG=INFO export FLAGCX_DEBUG_SUBSYS=ALL echo "FlagCX debug information enabled." else unset FLAGCX_DEBUG unset FLAGCX_DEBUG_SUBSYS echo "FlagCX debug information disabled." fi export FLAGCX_IB_HCA=mlx5 export FLAGCX_ENABLE_TOPO_DETECT=TRUE export FLAGCX_DEBUG=INFO export FLAGCX_DEBUG_SUBSYS=ALL export CUDA_VISIBLE_DEVICES=0,1 # 需要预加载为 FlagCX 链接指定的自定义 gloo 库 # export LD_PRELOAD=/usr/local/lib/libgloo.so # export LD_PRELOAD=/usr/local/nccl/build/lib/libnccl.so export TORCH_DISTRIBUTED_DETAIL=DEBUG CMD='torchrun --nproc_per_node 2 --nnodes=1 --node_rank=0 --master_addr="localhost" --master_port=8281 example.py' echo $CMD eval $CMD
torchrun的参数如下:nproc_per_node:当前机器上启动的进程数。nnodes:参与训练的总节点数。 对于同构模式测试,设置为 1。node_rank:当前节点在所有节点中的 rank,从 0 开始。 对于同构模式测试,设置为 0。master_addr:主节点的地址(主机名或 IP)。 对于同构模式测试,设置为"localhost"即可。 对于异构模式测试,指定主节点的可达 IP 或主机名。 假设该地址可以从所有节点访问。master_port:主节点用于建立进程组的端口。 所有节点必须使用相同的端口,且该端口在所有节点上必须可用。example.py:Torch API 测试脚本。参见 FlagCX 环境变量 了解各种
FLAGCX_XXX环境变量的用法。
正确性能测试的示例截图

使用 FlagCX + FlagScale 进行同构训练#
以下步骤展示了在 NVIDIA A800 GPU 上运行 LLaMA3-8B 模型的示例。
构建与安装
参见 快速开始 页面中的环境配置和构建安装部分。
数据准备
cd FlagScale mkdir data
提供了一小部分来自 Pile 数据集的处理数据(bin 和 idx 文件):
pile_wikipedia_demo。 将其复制到FlagScale/data目录。模型配置 1
cd FlagScale/examples/llama3/conf/ vi train.yaml
该目录包含以下文件:
train/— 训练脚本和相关文件。train.yaml— 同构训练 配置文件train.yaml文件包含四个主要部分:defaults、experiment、action和hydra。 大多数情况下,您只需要修改defaults和experiment部分。修改
defaultstrain: XXXX
将
XXXX替换为8b。修改
experimentexp_dir: ./outputs_llama3_8b
这指定了分布式训练结果的输出目录。
修改
experiment下的runner设置hostfile:对于同构(单节点)模式测试,注释掉
hostfile行。 仅在异构(多节点)模式设置时配置。envs:使用
CUDA_VISIBLE_DEVICES设置 GPU 设备 ID,例如:CUDA_VISIBLE_DEVICES: 0,1,2,3,4,5,6,7
train_hetero.yaml— 异构训练 配置文件
模型配置 2
对应不同数据集大小的模型配置文件(
xxx.yaml)位于examples目录中。cd FlagScale/examples/llama3/conf/train vi 8b.yaml
8b.yaml配置文件8b.yaml文件包含三个主要部分:system、model 和 data。System 部分
添加以下行以启用 FlagCX 分布式训练:
distributed_backend: flagcx
Model 部分
配置训练参数。使用
train_samples和global_batch_size确定步数:step = train_samples / global_batch_size
建议设置为整数。
Data 部分
修改以下参数:
data_path:设置为上一步准备的数据下的
cache目录。tokenizer_path:从模型对应的官方网站下载 tokenizer 并在此设置路径。
下载 tokenizer
下载模型对应的 tokenizer。 文件可从以下地址获取:Meta-LLaMA-3-8B-Instruct Tokenizer。
建议通过命令行下载 tokenizer。 将下载的 tokenizer 文件放在配置(
8b.yaml)中tokenizer_path指定的路径中。例如:
cd FlagScale/examples/llama3 modelscope download --model LLM-Research/Meta-Llama-3-8B-Instruct [XXXX] --local_dir ./
上述命令中的
[XXXX]指的是 Meta-LLaMA-3-8B-Instruct 对应的 tokenizer 文件。 内容可以是,例如:tokenizer.jsontokenizer_config.jsonconfig.jsonconfiguration.jsongeneration_config.json
这些文件应放在配置(
8b.yaml)中tokenizer_path指定的目录中。分布式训练
启动分布式训练:
cd FlagScale python run.py --config-path ./examples/llama3/conf --config-name train action=run
停止训练:
python run.py --config-path ./examples/llama3/conf --config-name train action=stop
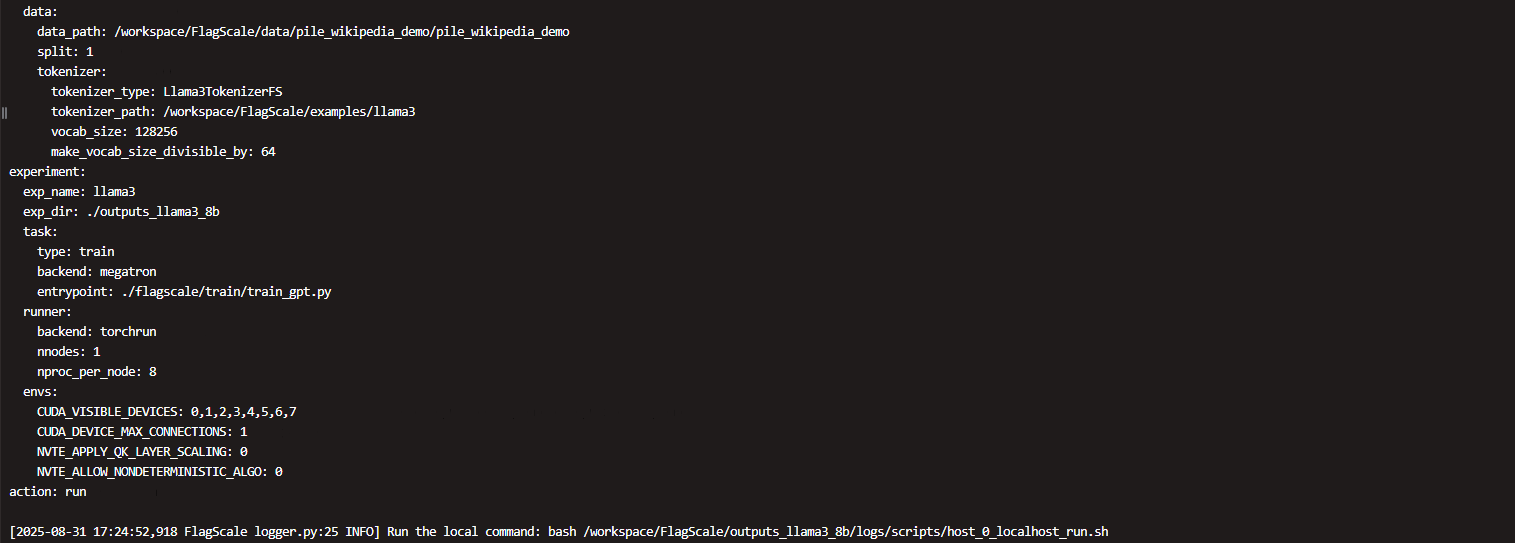
启动分布式训练后,将打印配置信息,并生成运行脚本:
flagscale/outputs_llama3_8b/logs/scripts/host_0_localhost_run.sh
训练输出文件可在
flagscale/outputs_llama3_8b下找到。注意事项:
您可以检查运行脚本以验证训练使用的命令和环境设置。
所有日志和模型检查点将保存在输出目录下。
使用 FlagCX 进行异构测试#
UniRunner 模式#
FlagCX 提供了一种统一的异构通信模式,称为 uniRunner,它实现了 11 个芯片解耦的集合通信算法。要启用 uniRunner 模式,在启动应用程序之前设置以下环境变量:
export FLAGCX_USE_HETERO_COMM=1
UniRunner 支持异构硬件上的所有标准集合操作(AllReduce、AllGather、ReduceScatter、Broadcast、Reduce、Gather、Scatter、AlltoAll、AlltoAllv、Send、Recv)。
对于使用 Device API 的基于内核的通信(在 NVIDIA 和 Hygon 上可用),您还需要:
export FLAGCX_MEM_ENABLE=1
参见 FlagCX 环境变量 获取 UniRunner 特定配置变量的完整列表(前缀为 FLAGCX_UNIRUNNER_*)。
单边 RDMA 操作#
FlagCX 支持由支持 RDMA 的网络适配器支持的异构通信器的单边 RDMA 操作。这些操作需要事先进行缓冲区注册。
缓冲区注册#
// 为单边 RDMA 操作(Get/Put/PutValue)注册缓冲区
// 集合操作:通信器中的所有 rank 必须调用
flagcxResult_t flagcxOneSideRegister(flagcxComm_t comm, void *buff, size_t size);
// 为单边 RDMA 操作注册信号缓冲区
// ptrType:FLAGCX_PTR_CUDA 表示设备内存,FLAGCX_PTR_HOST 表示主机固定内存
flagcxResult_t flagcxOneSideSignalRegister(flagcxComm_t comm, void *buff,
size_t size, int ptrType);
// 为 PutValue 操作注册主机固定暂存缓冲区
// 必须在 flagcxOneSideSignalRegister 之后调用
flagcxResult_t flagcxOneSideStagingRegister(flagcxComm_t comm, void *buff,
size_t size);
通过窗口注册的替代方式:
// 分配内存
flagcxMemAlloc(&ptr, size);
// 注册为单边操作的窗口
flagcxCommWindowRegister(comm, ptr, size, &win, FLAGCX_WIN_DEFAULT);
单边 API#
API |
描述 |
|---|---|
|
RDMA READ:从远程对等节点的缓冲区拉取数据到本地缓冲区 |
|
RDMA WRITE:从本地缓冲区推送数据到远程对等节点的缓冲区 |
|
批量 RDMA WRITE:针对多个小传输进行优化 |
|
RDMA WRITE + ATOMIC:写入数据,然后原子地递增远程信号 |
|
将立即值写入远程缓冲区 |
|
仅信号:原子地递增远程信号 |
|
等待本地信号达到预期值 |
|
读取当前全局 RMA 完成计数器 |
|
阻塞直到 RMA 完成计数器达到目标值 |
示例 - 使用完成计数器的异步 RDMA:
uint64_t before;
flagcxReadCounter(comm, &before);
flagcxPut(comm, peer, srcOffset, dstOffset, size, srcMrIdx, dstMrIdx);
flagcxWaitCounter(comm, before + 1); // 等待 Put 完成
清理:
flagcxCommWindowDeregister(comm, win);
flagcxMemFree(ptr);
参见 flagcx/include/flagcx.h 获取完整的 API 签名和参数文档。
P2P 引擎#
FlagCX P2P 引擎为单边 RDMA 操作提供点对点引擎接口,专为与 NIXL 等传输框架集成而设计。
主要特性#
连接管理(连接/接受远程对等节点)
RDMA 操作的内存注册
单边 READ/WRITE(RDMA Get/Put)
向量和批量操作
双边 send/recv
带外信令的通知系统
节点内 GPU 内存共享的 IPC 辅助工具
引擎生命周期#
// 创建并初始化 P2P 引擎实例
FlagcxP2pEngine *flagcxP2pEngineCreate();
// 销毁引擎实例
void flagcxP2pEngineDestroy(FlagcxP2pEngine *engine);
// 停止接受线程
void flagcxP2pEngineStopAccept(FlagcxP2pEngine *engine);
连接管理#
// 连接到远程对等节点
FlagcxP2pConn *flagcxP2pEngineConnect(FlagcxP2pEngine *engine,
const char *ipAddr, int remoteGpuIdx,
int remotePort, bool sameProcess);
// 接受传入连接(阻塞)
FlagcxP2pConn *flagcxP2pEngineAccept(FlagcxP2pEngine *engine, char *ipAddrBuf,
size_t ipAddrBufLen, int *remoteGpuIdx);
// 检查连接是否为节点内(支持 IPC)
bool flagcxP2pEngineConnIsLocal(FlagcxP2pConn *conn);
内存注册#
// 为 RDMA 注册内存区域
int flagcxP2pEngineReg(FlagcxP2pEngine *engine, uintptr_t data, size_t size,
FlagcxP2pMr &mrId);
// 注销内存区域
void flagcxP2pEngineMrDestroy(FlagcxP2pEngine *engine, FlagcxP2pMr mr);
// 为已注册区域准备 RDMA 描述符
int flagcxP2pEnginePrepareDesc(FlagcxP2pEngine *engine, FlagcxP2pMr mr,
const void *data, size_t size, char *descBuf);
单边操作#
// 单边读取(非阻塞)
int flagcxP2pEngineRead(FlagcxP2pConn *conn, FlagcxP2pMr mr, const void *data,
size_t size, FlagcxP2pRdmaDesc desc,
uint64_t *transferId);
// 单边写入(非阻塞)
int flagcxP2pEngineWrite(FlagcxP2pConn *conn, FlagcxP2pMr mr, const void *data,
size_t size, FlagcxP2pRdmaDesc desc,
uint64_t *transferId);
// 检查传输完成状态
bool flagcxP2pEngineXferStatus(FlagcxP2pConn *conn, uint64_t transferId);
参见 environment-variables.md 获取 P2P 引擎配置变量(FLAGCX_P2P_*)。
NCCL 包装插件#
对于 NVIDIA 平台,FlagCX 提供了一个 NCCL 包装插件,可构建直接替换的 libnccl.so。这允许任何基于 NCCL 的应用程序(PyTorch、DeepSpeed、Megatron-LM)透明地使用 FlagCX,无需修改代码:
# 构建包装器
cd FlagCX/plugin/nccl
make NCCL_HOME=/path/to/nccl CUDA_HOME=/path/to/cuda
# 与任何 NCCL 应用程序一起使用
LD_PRELOAD=./build/lib/libnccl.so python your_training_script.py
该包装器拦截 NCCL API 调用并通过 FlagCX 路由它们。线程本地递归保护可防止 FlagCX 内部 NCCL 适配器回调 NCCL 时出现无限递归。
前置条件:FlagCX 已构建并安装、CUDA 工具包、真实 NCCL >= 2.21.0(支持 2.21 到 2.27 版本)。详见 plugin/nccl/README.md。
通信 API 测试#
构建与安装
参见 快速开始 文档,了解环境配置、创建符号链接以及如何构建和安装软件的说明。
验证 MPICH 安装
检查是否已安装 MPICH:
cd /workspace/mpich-4.2.3
Makefile 和环境变量配置
# 进入通信 API 测试目录 cd /root/FlagCX/test/perf # 打开 Makefile vi Makefile # 修改 MPI 路径以匹配步骤 2 中使用的路径 MPI_HOME ?= /workspace/mpich-4.2.3/build/ :q # 保存并退出 # 配置环境变量 export LD_LIBRARY_PATH=/workspace/mpich-4.2.3/build/lib:$LD_LIBRARY_PATH异构通信 API 测试
确保 Host 1、Host 2、… 都按上述说明配置,并且可以在各自平台上正确运行同构通信 API 测试。
验证 Host 1、Host 2、… 上的端口为
<xxx>,并在所有主机上保持一致。在 Host 1 上运行异构通信 API 测试脚本之前,配置端口号环境变量:
export HYDRA_LAUNCHER_EXTRA_ARGS="-p 8010"
这里,
8010应与 SSH 免密登录期间设置的配置匹配。在 Host 1 上运行异构通信 API 测试脚本:
./run.sh
/workspace/mpich-4.2.3/build/bin/mpirun \ -np 2 -hosts 10.1.15.233:1,10.1.15.67:1 \ -env PATH=/workspace/mpich-4.2.3/build/bin \ -env LD_LIBRARY_PATH=/workspace/mpich-4.2.3/build/lib:/root/FlagCX/build/lib:/usr/local/mpi/lib/:/opt/maca/ompi/lib \ -env FLAGCX_IB_HCA=mlx5 \ -env FLAGCX_ENABLE_TOPO_DETECT=TRUE \ -env FLAGCX_DEBUG=INFO \ -env FLAGCX_DEBUG_SUBSYS=INIT \ /root/FlagCX/test/perf/test_allreduce -b 128K -e 4G -f 2 -w 5 -n 100 -p 1`
参见 FlagCX 环境变量 了解
FLAGCX_XXX环境变量的含义和用法。
注意: 在异构通信 API 测试中,当每个节点使用 2 个 GPU 时,某些警告可能指示每个节点只有 1 个 GPU 处于活动状态。在这种情况下,FlagCX 将跳过 GPU 到 GPU 的 AllReduce,回退到基于主机的通信。
结果是,GPU 利用率可能显示 0%,整体 AllReduce 运行时间可能更长。
但是,计算结果是正确的,这是预期行为。
要在异构测试中充分利用 GPU 加速,请在节点间使用 2+2 GPU(总共 4 个 GPU)。
