Features#
SGLang’s inference engine relies on NVIDIA-specific components: flashinfer for attention, sgl_kernel for fused CUDA kernels, and NCCL for distributed communication. Running on alternative hardware (Huawei Ascend, Cambricon MLU, Iluvatar, etc.) would otherwise require invasive source modifications.
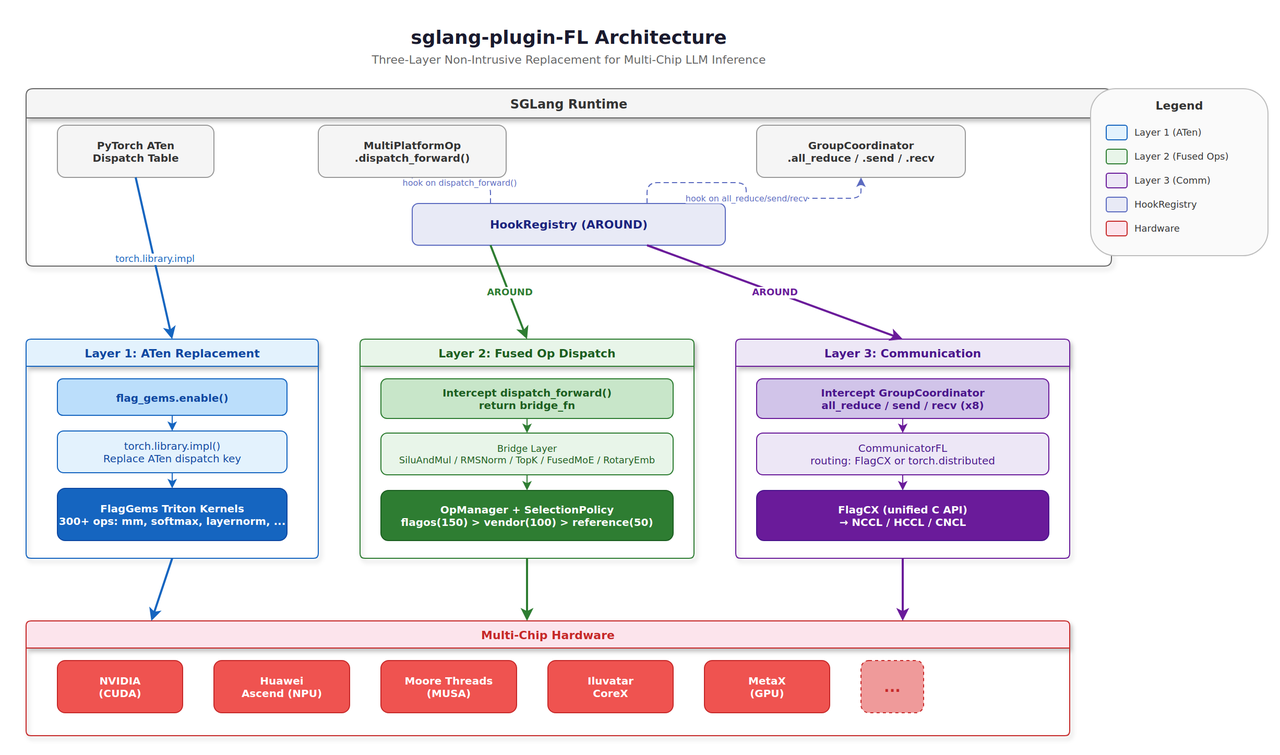
This plugin provides a non-intrusive adaptation layer through three levels of replacement:
Layer 1 — ATen Operators#
Replaces PyTorch’s low-level ops (matmul, softmax, embedding, etc.) with FlagGems Triton kernels via PyTorch’s dispatch mechanism. When flag_gems.enable() is called, the PyTorch dispatch table registers Triton kernels for ATen ops, providing hardware-accelerated implementations without code changes.
Layer 2 — SGLang Fused Kernels#
Intercepts SGLang’s custom fused ops (SiluAndMul, RMSNorm, RotaryEmbedding) via HookRegistry AROUND hooks, routing through a standardized dispatch system (aligned with vllm-plugin-FL) to select the best available backend:
FlagGems — Triton-based implementations (default, highest priority)
Vendor — Chip-native implementations (e.g., CUDA sgl_kernel, Ascend CANN)
Reference — Pure PyTorch fallback implementations
Layer 3 — Distributed Communication#
Replaces NCCL-based collectives with CommunicatorFL (backed by FlagCX or torch.distributed), enabling multi-card inference on any hardware. Supports all_reduce, all_gather, reduce_scatter, send, and recv operations.
Chip vendors only need to implement a backend class + register_ops.py. The dispatch system’s auto-discovery mechanism handles the rest. The same vendor implementations work across both sglang-plugin-FL and vllm-plugin-FL.