基准结果#
KernelGenBench 评估实验的关键发现。
多源结果#
在 NVIDIA A100 上对来自三个来源(ATen、vLLM、cuBLAS)的 210 个算子进行评估。
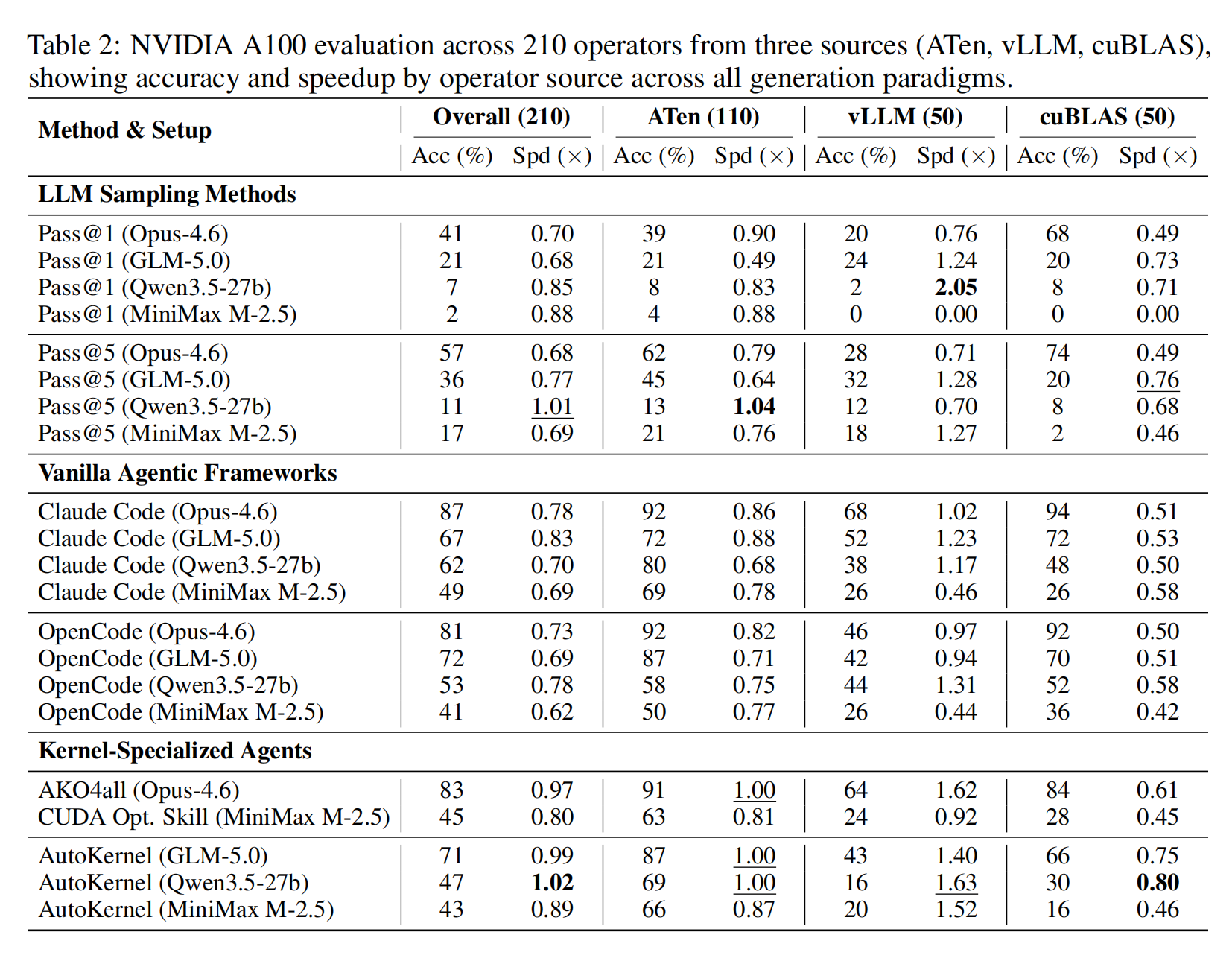
关键发现#
发现 |
详情 |
|---|---|
最高精度 |
Claude Code (Opus-4.6) 达到 87% |
最高加速比 |
AutoKernel (Qwen3.5) 达到 1.02× |
最具挑战性 |
所有方法的 cuBLAS 算子 |
按算子来源#
来源 |
最佳精度 |
最佳加速比 |
|---|---|---|
ATen |
92% (Claude Code) |
1.00× (AKO4ALL) |
vLLM |
68% (Claude Code) |
1.63× (AutoKernel) |
cuBLAS |
94% (Claude Code) |
0.71× (多种方法) |
多芯片结果#
在 6 个硬件平台上对 110 个 ATen 算子进行跨平台评估。
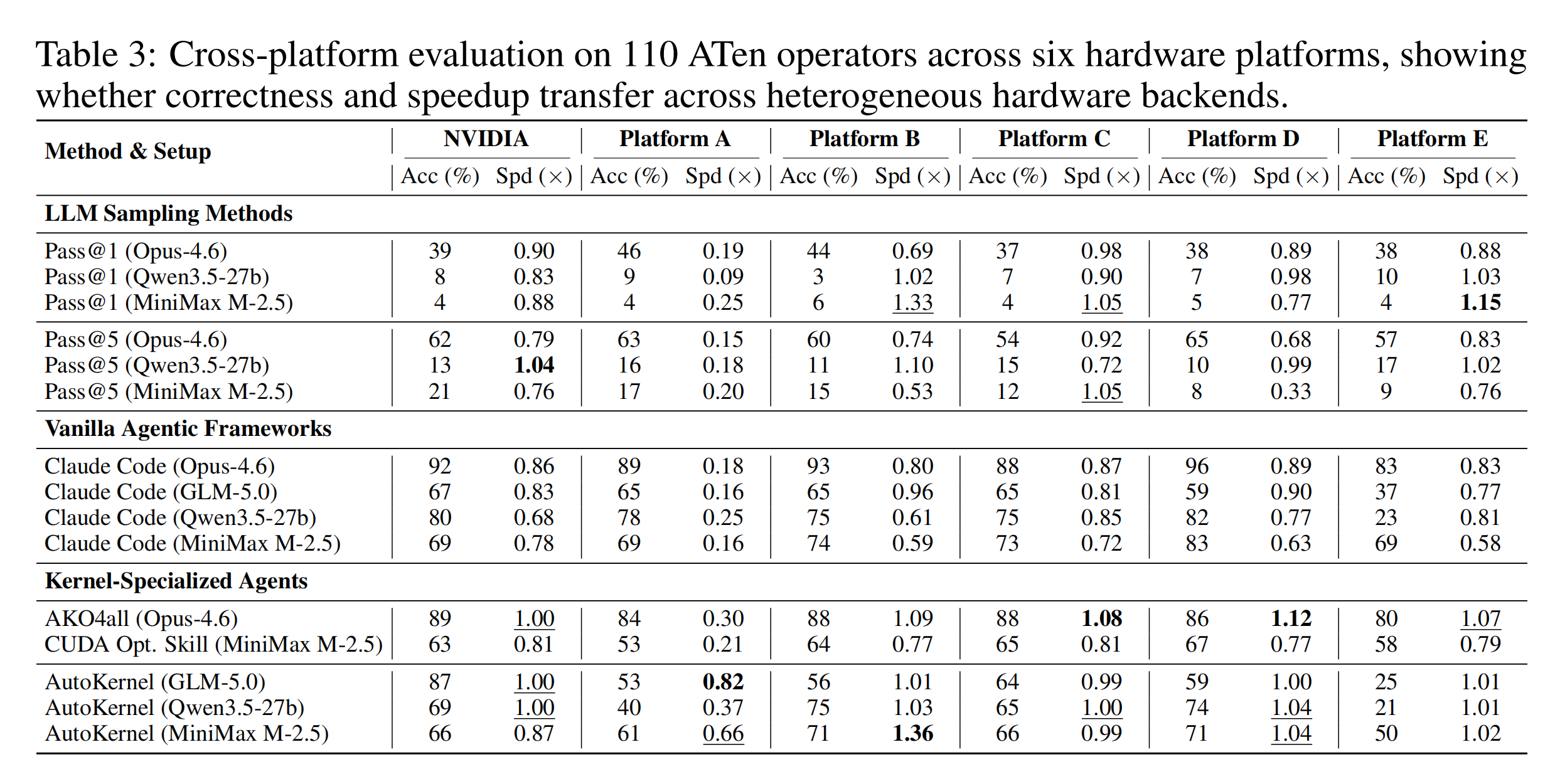
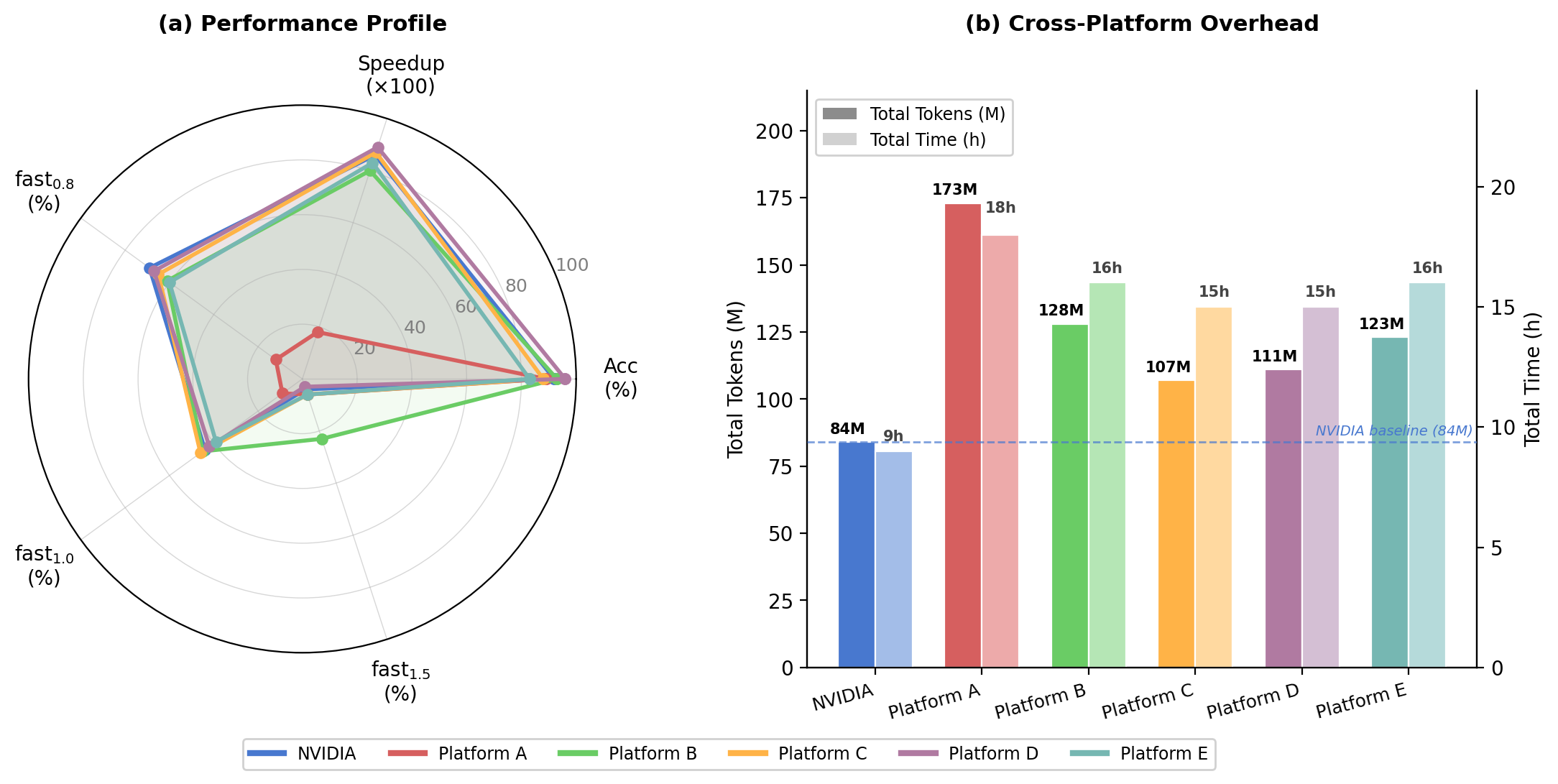
关键发现#
发现 |
详情 |
|---|---|
平台差异 |
生成性能在不同硬件间差异显著 |
跨平台性能下降 |
AutoKernel 从 87%(NVIDIA)下降到 25%(平台 E) |
编译器成熟度影响 |
非 NVIDIA 平台需要 2 倍或更多的 Token 和时间 |
各平台精度#
平台 |
Claude Code |
AKO4ALL |
|---|---|---|
NVIDIA |
87% |
83% |
平台 A |
~70% |
~60% |
平台 B |
~65% |
~55% |
平台 C |
~60% |
~45% |
平台 D |
~55% |
~35% |
平台 E |
~45% |
~25% |
成本分析#
方法 |
每次成功所需 Token |
|---|---|
Pass@5 |
~50K |
Claude Code |
~500K |
AKO4ALL |
~5.19M |
警告
大规模智能体评估可能消耗数十亿 Token。请相应规划您的预算。