TransformerEngine-FL 概览#
TransformerEngine-FL 是 NVIDIA Transformer Engine(TE)的一个分支,引入了基于插件架构的多 AI 芯片支持,构建在 FlagOS(统一开源 AI 系统软件栈)之上。它将 TE 的 FP8 训练和推理能力扩展到多种硬件环境中。在不改变 TE 原有接口或使用方式的情况下,相同的模型代码可以在不同 AI 芯片平台上运行 FP8 混合精度训练和推理。
Transformer Engine(TE)是一个用于在 NVIDIA GPU 上加速 Transformer 模型的库,包括在 Hopper、Ada 和 Blackwell GPU 上使用 8 位浮点(FP8)精度,以更低的显存占用来提供更好的训练和推理性能。TE 提供了一系列针对流行 Transformer 架构的高度优化构建模块,以及一个类似于自动混合精度的 API,可以无缝地与您的框架特定代码一起使用。TE 还包含一个与框架无关的 C++ API,可以与其他深度学习库集成,为 Transformer 启用 FP8 支持。
架构#
TransformerEngine-FL 采用三层插件架构,将算子管理与硬件特定实现解耦。
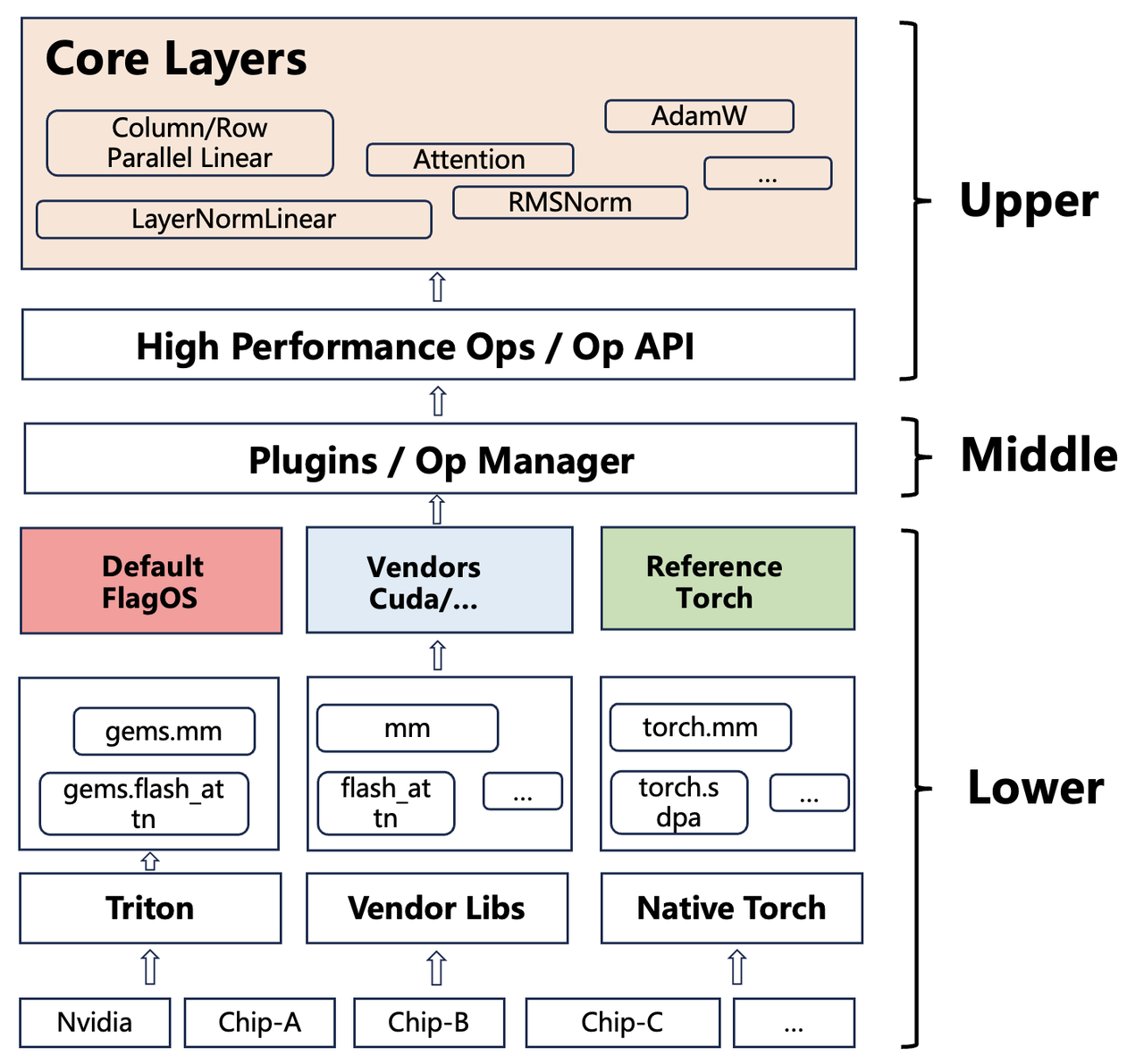
上层 — 核心 API 保持不变。TEFLModule 初始化插件系统并抽象出算子 API 层。CppExtension/Pybind 绑定 TEFLModule 以执行选定的后端内核。
中层 — OpManager 作为核心调度中心,协调 OpRegistry(线程安全的算子注册)、SelectionPolicy(支持 prefer/strict/per-op 配置的后端选择)和 Discovery(通过 Python Entry Points 和环境变量自动检测插件)。
下层 — 三种后端类型:FlagOS(默认,基于 Triton 的跨平台实现)、Vendor(硬件特定的优化实现,支持 In-Tree 和 Out-of-Tree 插件)和 Reference(纯 PyTorch 回退,保证正确性)。
插件系统#
TransformerEngine-FL 在 transformer_engine/plugin/ 中添加了基于插件的算子调度系统。它允许在运行时注册和选择替代的后端实现,无需修改核心库即可实现多芯片支持。
插件系统包括:
OpRegistry:线程安全的算子实现注册表
OpManager:核心调度管理器,选择最佳可用后端
SelectionPolicy:可配置的后端选择策略
Discovery:通过环境变量和 setuptools entry points 发现插件
后端优先级#
类型 |
优先级 |
描述 |
|---|---|---|
DEFAULT (FlagOS) |
150 |
基于 FlagGems 的实现 |
VENDOR |
100 |
供应商特定的实现 |
REFERENCE |
50 |
PyTorch 原生实现 |
支持的供应商请参见支持的硬件。